HashMap.
Serie - Fundamentos de Estrutura de Dados Elementar com Java.
HashMap. Como funciona o Hash Table.
O HashMap, também conhecido como Hash Table, Hash Map, ou até Dictionary, é uma estrutura baseada em tabelas de hash.
Opcional: Não sabe o que é hash? Veja um pequeno resumo aqui.
Essas tabelas são essencialmente arrays dinâmicos de objetos Node, que armazenam pares chave-valor.
/**
* A tabela (array), inicializada no primeiro uso e redimensionada conforme necessário.
*/
transient Node<K,V>[] table;
O papel do Hash
A singularidade das chaves é crucial no HashMap. A key é única, garantindo que nenhum objeto tenha o mesmo identificador. Esse identificador, ou hash, é gerado automaticamente a partir da key. Surpreendentemente, o hashCode() do Java, responsável por gerar esses hashes, não é tão eficiente para garantir unicidade.
Então, por que gerar hash da key? A resposta reside na eficiência da busca. Utilizando hash para localizar objetos é significativamente mais rápido do que comparações diretas, especialmente quando a key é uma string ou um objeto complexo. O hashCode() gera números, o que acelera ainda mais a busca.
Opcional: Sobre o hashCode() de Java.
Estrutura Interna da Tabela de Hash
A tabela de hash é um array dinâmico de objetos Node, cada um contendo informações cruciais:
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
Além de armazenar key e value, cada Node guarda o hash gerado a partir da key. O atributo next é essencial para lidar com colisões de hash (veremos mais a frente), um conceito vital para a integridade da estrutura.
Exemplo Prático:
Considere o seguinte exemplo:
var names = new HashMap<Integer, String>();
names.put(1, "John Doe");
names.put(2, "Jane Doe");
names.put(3, "Aulus");
System.out.println(names);
names.put(3, "Agerius");
System.out.println(names.get(3));
Output (clique)
{1=John Doe, 2=Jane Doe, 3=Aulus}
Agerius
imagem mental:
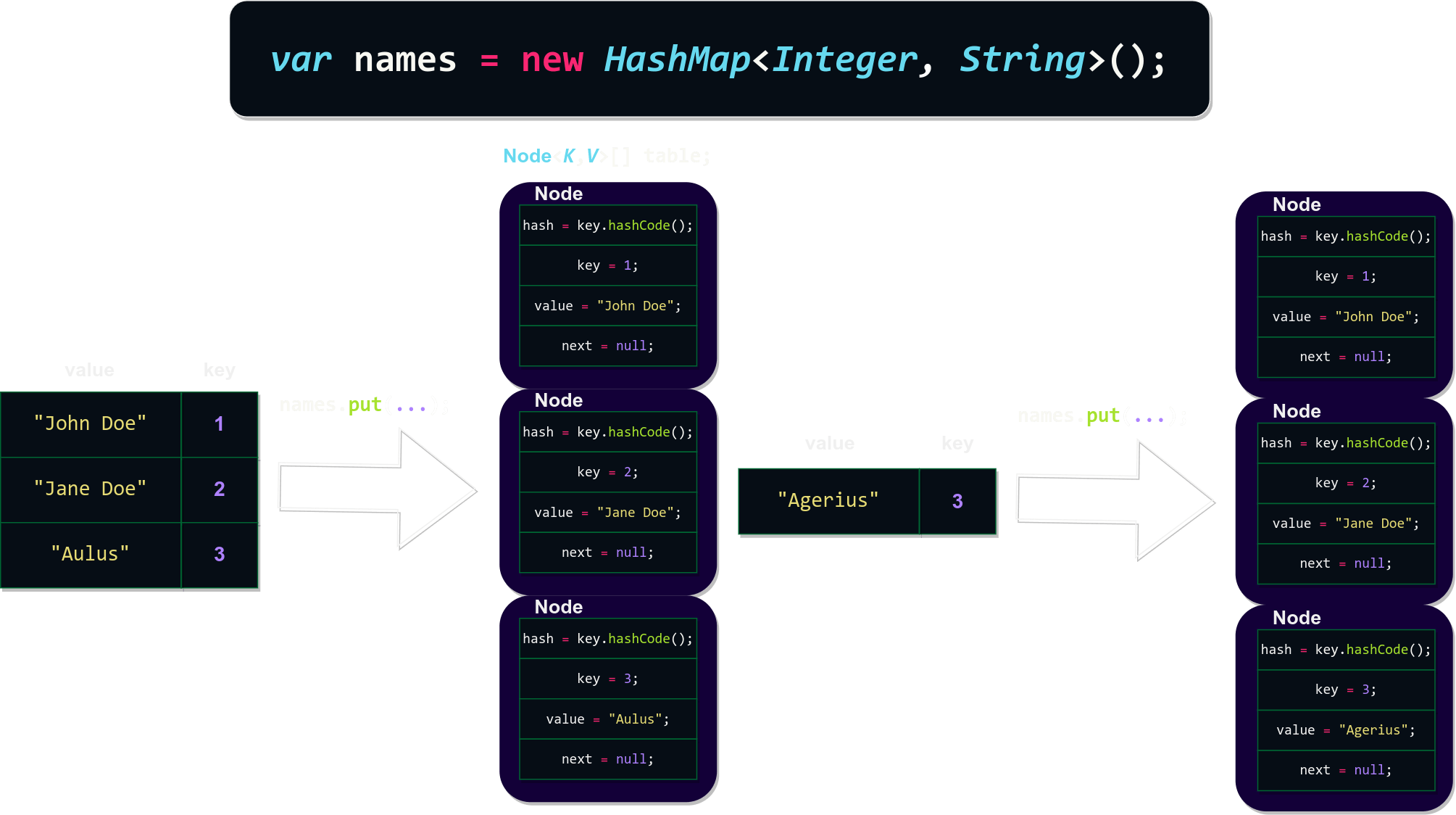
Note a key três tendo o value substituido, isto claro pois não pode haver 2 keys mapeando para o mesmo value.
Colisões de hash no HashMap.
Ao explorarmos as nuances do HashMap, deparamo-nos com um desafio intrigante: as colisões de hash. Conforme sabemos, uma função hash pode, eventualmente, produzir o mesmo valor hash para entradas distintas. Essa probabilidade é ainda maior quando se trata da função hashCode(). Agora, como enfrentamos essa questão em nossa estrutura HashMap? Como realizamos buscas por elementos usando a chave quando dois ou mais elementos compartilham o mesmo hash? E, se uma colisão resultar em dados sendo sobrepostos?
Lidando com Colisões de hash.
A justificativa para representar a tabela como um array de Nodes torna-se evidente quando ocorrem colisões. Nesse momento, a estrutura identifica duas chaves diferentes que geram o mesmo hash. A solução é conectar Nodes com o mesmo hash, assemelhando-se à lógica de uma LinkedList. Contudo, aqui, é uma lista ligada simples, não duplamente ligada.
Quando ocorre uma colisão, o atributo next do Node aponta para outro Node com uma chave diferente, mas com o mesmo hash. Durante uma pesquisa usando a chave, a estrutura gera o hash correspondente e inicia na posição head (primeiro Node na sequência ligada). Se a chave não corresponder à do Node atual, a estrutura passa para o próximo Node usando o atributo next.
Nota: Essa sequência de Nodes ligados é englobada por algo que chamamos de
Buckets, uma representação visual que facilita a compreensão, embora não exista no código fonte.
Exemplo Prático:
Para tornar isso mais tangível, consideremos as chaves como nomes de pessoas em String e os valores como CPF. Vamos usar duas chaves "FB" e "Ea", gerem o mesmo hash pela função hashCode().
código:
System.out.println("Hash FB: " + "FB".hashCode());
System.out.println("Hash Ea: " + "Ea".hashCode());
var persons = new HashMap<String, String>();
persons.put("gulybyte", "892.122.468-85");
persons.put("Aulus", "074.698.458-87");
persons.put("FB", "112.423.435-71");
persons.put("Donald Knuth", "822.923.975-44");
persons.put("Ea", "440.932.950-26");
System.out.println(persons.get("FB"));
Output (clique)
Hash FB: 2236
Hash Ea: 2236
112.423.435-71
imagem mental:
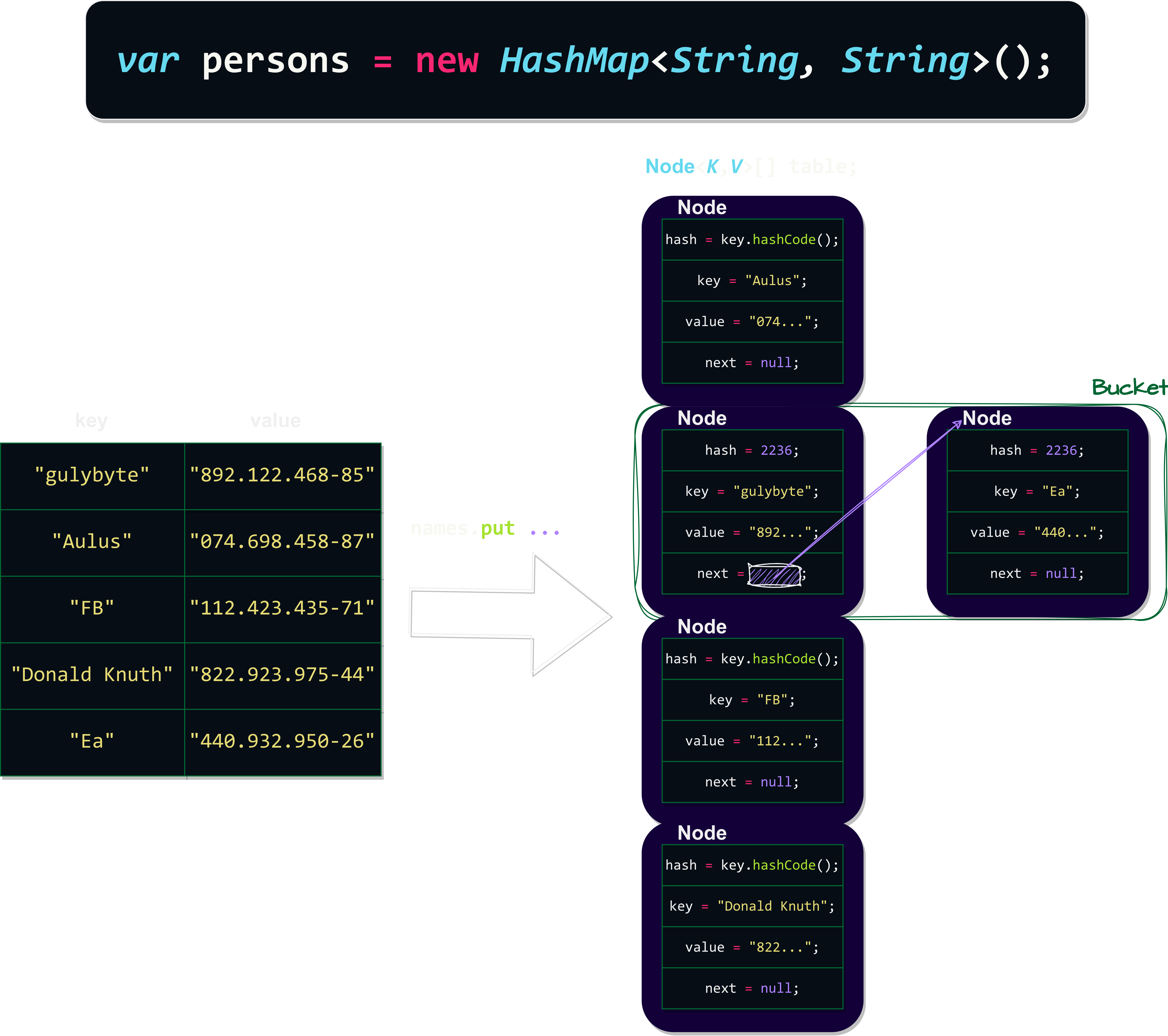
Uma estrutura que contém outra estrutura de dados. Fascinante, não é mesmo?
Para realizar pesquisas sem retornar múltiplos elementos, a estrutura verifica dentro do bucket para encontrar a chave correspondente, em vez de se basear apenas no hash gerado.
Opcional: Casos de Colisões Extremas
No contexto de BigData, surge a pergunta: e se houver muitas colisões? A busca em uma lista ligada pode se tornar um problema (assim como visto em LinkedList). Para esses casos, o HashMap emprega uma estratégia adicional: em vez de usar Nodes ligados, recorre a uma estrutura chamada Tree (ou árvore). Quando um bucket contém mais de 8 Nodes (não é uma regra), os dados são transferidos para uma Tree. Embora essa mudança gere uma pesquisa mais eficiente em casos de muitas colisões, ela dobra a complexidade espacial em comparação com a abordagem de Nodes.
Mas por que não usar Trees desde o início? Além de ser uma solução raramente necessária, as Trees ocupam o dobro do espaço em memória de um bucket com Nodes. Assim, a estratégia de transferir dados para uma Tree é acionada apenas em casos excepcionais, garantindo uma implementação eficiente na maioria das situações.
Como funciona essa Tree? Essa Tree usada como segunda estrategia para lidar com colisões, é quase a mesma que TreeMap, que será uma estrutura que veremos em breve. Não se preocupe quanto ao funcionamento minucioso desta 2º estrategia, ficara de fácil compreensão depois de vermos de a estrutura TreeMap.
Quanta Complicação -_-
Então, por que toda essa complexidade? Não seria mais simples evitar o hash e realizar pesquisas diretas pela chave? Apesar das complicações, o hash oferece rapidez na pesquisa, tornando o processo altamente eficiente. Se a velocidade de pesquisa não é uma prioridade, talvez essa estrutura não seja a mais adequada.
Vantagens e Desvantagens
Vantagens
1- Fornece acesso rápido aos elementos por meio de chaves.2- Implementa um algoritmo de tabela de hashing eficiente. Ótimo para mapeamento de chaves para valores em grandes conjuntos de dados.
Desvantagens
1- Não garante a ordem dos elementos e pode levar a colisões, o que pode afetar o desempenho em casos específicos.2- Sua função de hash não evita muitas colisões frequentes.
Uso comum
Mapeamento eficiente de chaves para valores, útil em indexação e pesquisa.
Cenário de uso: Em um sistema de gerenciamento de cache, um HashMap pode ser utilizado para armazenar resultados de consultas recentes, permitindo a rápida recuperação dos resultados sem a necessidade de recálculos.